
Por Werner Vogels, CTO de Amazon.com.
Una pregunta que suelen hacerme con cierta frecuencia es: ¿por qué ofrecemos tantos productos diferentes para bases de datos? Desde mi punto de vista, la respuesta es sencilla: los desarrolladores buscan que sus aplicaciones cuenten con una arquitectura sólida y sean capaces de variar de escala de forma eficaz. Para ello, necesitan poder utilizar múltiples bases y modelos de datos dentro de una misma aplicación.
Pocos son los casos en los que una única base de datos puede cubrir las necesidades de múltiples casos de usos diferentes. Los días de las bases de datos monolíticas que valían para todo ya han pasado. Hoy en día, los desarrolladores crean aplicaciones altamente distribuidas empleando un sinfín de bases de datos estructuradas específicamente para ellas. Los desarrolladores siguen haciendo lo que siempre ha sido su especialidad: descomponer aplicaciones complejas en componentes más pequeños, eligiendo así las mejores herramientas para resolver cada problema. La mejor herramienta para una tarea suele variar en función del uso que se le vaya a dar.
Durante décadas, al ser las bases de datos relacionales la única opción disponible, independientemente de la forma o función de los datos que contenía la aplicación, modelábamos los datos siguiendo un modelo relacional. En lugar de ser el caso de uso el que definía los requisitos que la base de datos debía cumplir, la realidad era a la inversa. Eran las bases de datos las que imponían un modelo de datos, que las aplicaciones debían utilizar. Pero las bases de datos relacionales, ¿no están específicamente diseñadas para esquemas no normalizados y para asegurar la integridad referencial de la base de datos? Por supuesto, pero la clave a la que quiero llegar es que no todos los modelos de datos para aplicaciones o casos de uso encajan dentro del modelo relacional.
Como ya he analizado anteriormente, una de las razones que nos llevó a crear DynamoDB en su momento era que Amazon estaba llegando a los límites de lo que era posible con la que era una de las mejores base de datos para comercios de su tiempo. Nos veíamos incapaces de cubrir las necesidades en materia de disponibilidad, escalabilidad y rendimiento que exigía el rápido crecimiento de Amazon.com. Investigando, descubrimos que aproximadamente un 70% de nuestras operaciones eran consultas de clave-valor, en las que sólo se utilizaba una clave principal y el resultado era una única entrada. Al no requerir integridad referencial ni transacciones referenciales, llegamos a la conclusión de que sería mejor responder a estos patrones de acceso mediante una base de datos que siguiera un modelo diferente. Además, ante el rápido crecimiento y la gran escala de Amazon.com, el tener una capacidad de escalabilidad horizontal prácticamente ilimitada pasó a ser un elemento clave en el diseño de nuestras soluciones. Aumentar la escala según fuera necesario simplemente no era una opción. Finalmente fue esto lo que llevó a la creación de DynamoDB, un servicio de bases de datos no relacionales diseñado para incrementar su escala más allá de lo posible utilizando bases de datos relacionales.
No quiero decir con esto que las bases de datos relacionales no puedan ser de utilidad en el desarrollo actual, ni que sean incapaces de ofrecer gran disponibilidad, escalabilidad o rendimiento. Muy al contrario. De hecho, esto es algo que nuestros clientes han dejado patente, ya que Amazon Aurora continúa siendo el servicio de más rápido crecimiento en la historia de AWS. Lo que vivimos con Amazon.com era un ejemplo de uso de una base de datos más allá de su propósito inicial. Este tipo de lecciones es una de las claves de este artículo: las bases de datos se crean con una finalidad y alinear el caso de uso con la naturaleza de la base de datos os ayudará a acelerar vuestros proyectos de desarrollo de aplicaciones de alto rendimiento y gran funcionalidad y disponibilidad.
Bases de datos diseñadas a medida
El mundo cambia constantemente y, de un modo similar, los tipos de bases de datos no relacionales continúan aumentando en número. Con cada vez más frecuencia, vemos cómo nuestros clientes buscan crear aplicaciones para uso a través de Internet que requieren varios modelos de datos. Para responder a estas necesidades, los desarrolladores de hoy en día pueden elegir entre bases de datos como las relacionales, las de clave-valor, documentales, orientadas a grafos, en memoria o de búsqueda. Cada uno de estos tipos de bases de datos permite solucionar un tipo o tipos de problemas concretos.
Veamos en mayor detalle la finalidad de cada uno de estos tipos de bases de datos:
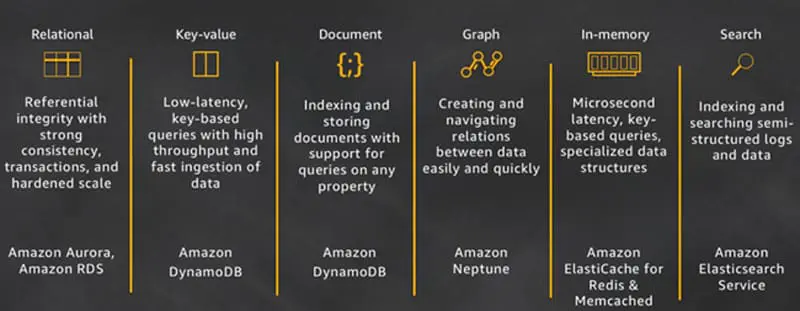
- Bases de datos relaciones:una base de datos relacional es autodescriptiva por cuanto permite a los desarrolladores definir el esquema de la base de datos, además de las relaciones y limitaciones entre las filas y tablas que la componen. Al usar bases de datos relacionales, los desarrolladores se valen de la funcionalidad de la base de datos (y no del código de la aplicación) para implementar el esquema y preservar la integridad referencial de los datos. Los casos de uso más habituales para bases de datos relacionales incluyen aplicaciones móviles y web, aplicaciones empresariales y plataformas de juego online. Airbnb es un gran ejemplo de cliente que ha creado aplicaciones de gran escalabilidad y alto rendimiento empleando Amazon Aurora. Esta solución ofrece a Airbnb un servicio funcional, escalable y totalmente gestionado con el que cubrir sus cargas de trabajo MySQL.
- Bases de datos clave-valor: estas bases de datos son muy fáciles de particionar y permiten variar de escala horizontalmente con una facilidad que otras bases de datos son incapaces de alcanzar. Entornos como los de los videojuegos, la publicidad y el Internet de las Cosas se prestan a bases de datos estructuradas en torno a este modelo, en el que se requieren consultas y entradas de datos con una latencia muy reducida para claves ya conocidas. El objetivo de DynamoDB es ofrecer latencias de unos pocos milisegundos con gran homogeneidad, para cargas de trabajo de cualquier escala. Este rendimiento constante y homogéneo es un elemento muy importante en el éxito de la función Historias de Snapchat, que es la funcionalidad con mayor volumen de escritura a almacenamiento de todas cuantas opera Snapchat y que la compañía ha migrado recientemente a DynamoDB.
- Bases de datos documentales:las bases de datos documentales resultan intuitivas de utilizar para los desarrolladores, porque los datos a nivel de aplicación suelen estar representados en forma de documentos JSON. Así, los desarrolladores pueden hacer persistir los datos utilizando el mismo formato y modelo de documentos que utilicen en el código de su aplicación. Tinder es un ejemplo de un cliente que utiliza los modelos de esquemas flexibles que ofrece DynamoDB para aumentar la eficiencia de su desarrollo.
- Bases de datos orientadas a grafos:la finalidad de este tipo de bases de datos es facilitar el desarrollo y funcionamiento de aplicaciones que trabajen con conjuntos con altos niveles de interconexión. Entre los ejemplos de casos de uso para bases de datos orientadas a grafos encontramos redes sociales, motores de recomendación, sistemas de detección de fraudes y generadores de gráficos de conocimientos. Amazon Neptune es un servicio de bases de datos orientadas a grafos completamente gestionado. Neptune permite trabajar con modelos como Property Graph y RDF (Resource Description Framework), brindando al desarrollador la capacidad de elegir entre dos API: TinkerPop y RDF/SPARQL. Así, Neptune brinda a nuestros usuarios las herramientas para crear gráficos de conocimiento, ofrecer recomendaciones dentro de sus juegos y detectar fraudes. Thomson Reuters, por ejemplo, utiliza Neptune para asesorar a sus clientes, ayudándoles a lidiar con la compleja estructura global de políticas y normativas fiscales.
- Bases de datos en memoria:sectores como los de los servicios financieros, el eCommerce, las páginas web y las aplicaciones suelen presentar casos de uso como clasificaciones en directo, sesiones de compra y análisis de datos en tiempo real, que requieren tiempos de respuesta de unos microsegundos y que pueden presentar grandes picos de tráfico en cualquier momento. Para estos casos, creamos Amazon ElastiCache, que ofrece los sistemas Memcached y Redis, con los que dar respuesta a cargas de trabajo que requieran baja latencia y gran ancho de banda, como es el caso de McDonald’s, que no puede ver cubiertas sus necesidades empleando sistemas convencionales de almacenamiento en disco. Amazon DynamoDB Accelerator (DAX) es otro gran ejemplo de un sistema de almacenamiento de datos creado a medida de su uso. DAX fue creado para hacer que las consultas a través de DynamoDB fueran varias veces más rápidas.
- Bases de datos de búsqueda:muchas aplicaciones generan archivos de registro con el fin de ayudar a los desarrolladores a identificar y resolver posibles problemas. El servicio Amazon Elasticsearch (Amazon ES) ha sido creado específicamente para ofrecer visualizaciones y análisis de conjuntos de datos generados por máquinas prácticamente en tiempo real, mediante el indexado, agregación y búsqueda en archivos de medición y en registros semiestructurados. Amazon ES es, además, un potente motor de búsqueda de alto rendimiento para búsquedas de texto. Expedia, por ejemplo, utiliza más de 150 dominios de Amazon ES, 30 TB de datos y 30.000 millones de documentos para cubrir toda una serie de aplicaciones críticas para su funcionamiento, que van desde la monitorización de sus operaciones y la resolución de posibles problemas, al stack tracing de aplicaciones distribuidas, pasando por la optimización de los precios.
De la misma forma en la que han dejado de desarrollar aplicaciones monolíticas, los desarrolladores están renunciando a utilizar una única base de datos para todos los posibles usos de su aplicación. En su lugar utilizan varias. Aunque las bases de datos relacionales aún gozan de buena salud y son muy válidas para muchas aplicaciones, las bases de datos creadas específicamente para modelos como los de clave-valor, documental, orientado a grafos, en memoria y de búsqueda pueden ayudaros a optimizar vuestra funcionalidad, rendimiento, escala y, lo que es más importante, la experiencia de vuestros clientes. No dejéis de crear.






